I must admit that, in my career so far, character encodings have been a pretty insignificant concern. Most of the software I write is focused on small, domestic audiences. So character sets mean 1-byte vs. 2-byte or a couple of garbage-ish characters at the top of some files. But, after reading Joel’s guidance on character sets, I’ve been more alert to them. I have a better understanding of how character sets work, and I’m paranoid about them causing trouble for me, though how exactly they work is still a bit of smoke and mirrors.
All that said, I helped Dave solve a character set problem yesterday.
In the footer of a site we work on is this: 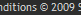
… except on some pages, where it looks like this: 
Interesting.
Dave knew that normal aspx pages showed the symbol correctly, while CGI pages showed  before ©. The CGI pages are handled by an ASP.NET handler that I wrote, which is why he came to ask me.
My spidey-sense whispered “character encoding,” so I started trying to figure out what the charsets were. I popped open Chrome’s developer tools and checked the headers on a plain ASP.NET page and an ASP.NET/CGI page.
ASP.NET: Content-type: text/html; charset=utf-8
CGI: Content-type: text/html; charset=ISO-8859-1
Ahha! It is a charset thing!
“But it says © in the source files,” Dave said. So why does charset matter? Does the browser really interpret ‘©’ differently based on which charset it’s using? Or is ASP.NET being “helpful” again?
I poked through the skin files, finding this:
<asp:Label
SkinID="FooterCopyrightText"
Text="Terms and Conditions © 2009 SEP"
runat="server" />It looks OK, but because ASP.NET is the consumer of the skin file, ASP.NET is interpreting the © entity and storing it in a string as the character with code point A9. When it writes out the page, it doesn’t bother figuring out whether to make it an entity again (I wouldn’t either), so it outputs the UTF-8 encoding for A9, which is C2A9. To complete our comedy, and in an effort to avoid garbling the CGI output (which is, in fact, more important to get right than the copyright symbol in the footer of the page), the CGI handler is changing the Content-type header to match what the CGI program says it is (ISO-8859-1). In ISO-8859-1, C2A9 is ©.
The quick fix was to change the © to &copy; in the skin file so that ASP.NET actually renders ©. The complete fix will be either to align the encoding used by ASP.NET and CGI, or to modify the CGI handler to translate the CGI output from ISO-8859-1 (or whatever encoding it’s using) to UTF-8.
